How to write fast Rust code

Since I wrote How to write really slow Rust code and its sequence, Part 2, I have received so much feedback and suggestions to make my Rust code run faster that I decided I had enough material to write another post, this time focusing on more advanced tools and techniques available to Rust developers rather than on how to avoid noobie mistakes that will totally destroy your Rust code performance, as the previous blog posts did.
If you’re new to Rust, it may be worthwhile looking at those posts first.
We ended up with a fairly optimized code base that was able to leave behind the Java and Common Lisp implementations (though they were not as optimized - which deserves another blog post)!
So, this time let’s focus on Rust and on what Rust developers can do to make their code go fast fast!
A quick recap
The previous blog post went into some detail about why the original Rust code was so slow. Let’s recap the main performance sins I’d committed so that you don’t need to make the same mistakes!
Careless allocations due to lack of understanding of Rust operators.
This might be surprising behaviour if you’re not used to thinking in Rust yet:
ERRATA: a previous version of the code below incorrectly distinguished between
n = n * 10u8andn *= 10u8. The actual issue is the RHS of the expression. If it’s a reference, it allocates, otherwise it doesn’t. This is actually the same bug I mentioned in the previous blog post: using the main branch of thenum-bigintrepository, the example using a reference will only allocate oneBigUint, theten, as one would’ve expected. In any case, the point is that one must know how the operator traits are implemented in order to know what an operator may return and whether it might allocate or not.
let mut n: BigUint = 1u8.into();
let ten: BigUint = 10u8.into();
// this will allocate a new BigUint
n = n * &ten;
// but this won't!
n = n * ten;
// neither will this
n *= ten;
Cloning more data than necessary.
Every piece of data has one, and only one owner in Rust. If you have a temporary data structure that, semantically,
doesn’t hold the “original” data and just “borrows” it from another one, then you should make sure that it contains
&Thing, not Thing.
// owner of Strings
let mut vec: Vec<String> = Vec::new();
vec.push("a".to_owned());
vec.push("b".to_owned());
{
// borrower
let mut temp_vec: Vec<&str> = Vec::new();
// ok, we only borrow the String as &str
temp_vec.push(&vec[0]);
}
{
// wants to take ownership
let mut greedy_vec: Vec<String> = Vec::new();
// we need to clone it, otherwise it wouldn't compile!
greedy_vec.push(vec[1].to_owned());
}
As we saw in the previous post, usage of data structures containing references usually require the use of lifetimes, but will allow you to avoid the cost of cloning data everywhere (and lifetimes may be difficult to understand in the beginning, but eventually you’ll get your head around them as the compiler tells you when and where you’ll need them).
Using an inefficient immutable data structure (more cloning).
This may be controversial, but there’s no denying: mutating data can be much more efficient than trying to keep everything immutable.
Specially when you use the basic Rust data structures, like Vec, which will require actually cloning the whole
structure on any operation as opposed to trying to do that efficiently using persistent data structures,
as certain functional languages do.
That’s why changing my code from this:
for word in found_words {
found_word = true;
let mut partial_solution = words.clone();
partial_solution.push(word);
print_translations(num, digits, i + 1, partial_solution, dict)?;
}
To this:
for word in found_words {
found_word = true;
words.push(word);
print_translations(num, digits, i + 1, words, dict)?;
words.pop();
}
… made my program around 16% faster (measured after the changes below to buffer printouts to avoid that bottleneck interfering too much)… but it forced me to introduce mutability and, consequently, variable lifetimes! In this case, it was not a big deal, but in a complex code base that could become a problem.
However, Rust has something that almost no other language has: it enforces ownership rules so that you can never have more than one mutable reference to a value. That makes mutability actually manageable as tracking mutable state becomes much easier: if your code holds a mutable reference, nothing else does. It also makes it possible to implement efficient persistent data structures!
I tried using a persistent list (rpds) instead of cloning the vector as in the “slow” implementation above, and it performed almost exactly the same (just a little slower, in fact).
Hint: don’t forget to always run Clippy, the Rust linting tool, after you make changes to some code as it will almost certainly uncover lots of basic mistakes you’re likely to make while you’re still learning (and even some you might make even after a few years doing Rust).
Naively printing to stdout directly
Finally, one of the biggest problems with my original code was something that most programmers might overlook entirely:
printing results to stdout.
Here’s what I was doing before:
print!("{}:", num);
for word in words {
print!(" {}", word);
}
println!();
This looks innocent enough, but if your program prints a lot of stuff, this will become a huge bottleneck because each
call to print! will first acquire a lock on stdout, then call format!,
to resolve the formatting, and finally make a syscall to actually print, all without buffering the data
(print! may be buffered until a new-line is found, but in the above case,
the println! call guarantees that the buffer will be flushed immediately every time this code runs).
Inefficient printing, even after buffering was introduced, was what made my Rust program slower than my Java port in previous blog posts! So, let’s look more deeply into what’s going on here by introducing a Rust benchmarking tool.
Using Criterion.rs to guide optimisations
Which implementation do you think is faster, the one above or the following, more straightforward one-liner:
println!("{}: {}", num, words.join(" "));
To find out, we can run both versions in a micro-benchmark using Criterion.rs.
Writing benchmarks with Criterion.rs is pretty easy, have a look at their great documentation to learn how to do it… you can see the code changes I had to make were pretty simple.
Because I am interested in the output Criterion prints to
stdout, I changed calls toprintln!toeprintln!and pipedstderrto/dev/null. Do not attempt to run this benchmark without doing that otherwise your terminal will be printing output for a long time!
It turns out this one-liner is not just somewhat faster, it’s A LOT faster!
Output from the first version (showing only largest sample - the time increases perfectly linear with the number of words to print):
phone_encoder/50 time: [56.935 us 57.239 us 57.556
thrpt: [868.72 Kelem/s 873.53 Kelem/s 878.20 Kelem/
Output from the simplified version:
phone_encoder/50 time: [2.3726 us 2.3925 us 2.4184 us]
thrpt: [20.675 Melem/s 20.899 Melem/s 21.074 Melem/s]
change:
time: [-95.830% -95.792% -95.752%] (p = 0.00 < 0.05)
thrpt: [+2254.1% +2276.5% +2298.0%]
Performance has improved.
Criterion prints a helpful result showing that performance has improved, indeed. It also generates nice plots with the benchmark results (but the difference between the two versions is so huge that showing the plot wouldn’t provide any extra information).
In my “macro” benchmark I had been using to compare the different implementations, this change is barely noticeable, though, as it still seems to be drowned by other more important factors.
In the previous blog post, I showed how buffering stdout, however, made a big difference. Let’s check how much difference Criterion thinks it makes.
phone_encoder/50 time: [474.38 ns 477.38 ns 480.52 ns]
thrpt: [104.05 Melem/s 104.74 Melem/s 105.40 Melem/
change:
time: [-80.278% -80.035% -79.746%] (p = 0.00 < 0.05)
thrpt: [+393.74% +400.88% +407.06%]
Performance has improved.
Another huge improvement!
In the macro benchmark, however, this is still only noticeable when there’s a very large number of solutions to print. Going back to the first part of this series: this implementation still has about the same performance as the Common Lisp implementation!
But we can go further, as we’ll see!
Optimisation attempts
Allocating small Vectors on the stack with smallvec
As you probably know, Vec is allocated on the heap. If you know your vectors are going to be of a small size, it may be worthwhile looking into smallvec, a crate that avoid heap allocation while providing an interface like Vec, which “spills into” the heap only if required.
I tried using that instead of Vec to hold words as I know that for the problem at hand, the maximum size of that vector is 50.
I used Criterion again to see if that might help, but the results were not good: performance actually decreased for all different parameters I tried (the best I managed was a 15% increase in time).
Running the macro benchmark confirmed that, at best, using SmallVec made no difference.
Using faster implementation of Big int
The crate I chose for representing big numbers was num-bigint because that’s one of the first options that show up when you look for it on crates.io (where it’s by far the most popular, with over 15 million downloads) or lib.rs (where it’s the first hit for me).
But there are many options, including rust-gmp, which is not pure Rust but links to the GNU GMP library, and ibig.
Luckily, the ibig maintainer has already benchmarked the different crates, showing that the GMP-based crates
are a lot faster than anything else.
I cannot recommend using
ibigat this time because it currently lacks implementations for the artihmetics traits for anything but its own types (so you can’t addu8,u16etc to aibig::UBig) and it panics when you try things likelet d = 1u8; ibig!(d), making it very unergonomic to use. There’s a Pull Request using that, if anyone is curious and wants to try it anyway.
I modified the implementation to use rug instead of num-bigint and ran my macro benchmark again.
To my surprise, using rug made the program visibly slower, approximately 20% slower to be exact.
The code changes were trivial, so I believe I didn’t make any big mistakes.
It took 6min30sec for my project to compile after adding rug to my dependencies, mostly due to the GMP sys dependency. I was expecting a huge speed up!
Here are the results (input sizes are 1,000, 10,000, 50,000, 100,000 and 200,000):
===> ./phone_encoder
Proc,Memory(bytes),Time(ms)
./phone_encoder,24612864,116
./phone_encoder,24600576,179
./phone_encoder,24625152,465
./phone_encoder,24612864,817
./phone_encoder,24584192,1530
===> ./phone_encoder_rug
Proc,Memory(bytes),Time(ms)
./phone_encoder_rug,21364736,111
./phone_encoder_rug,21393408,200
./phone_encoder_rug,21393408,543
./phone_encoder_rug,21397504,972
./phone_encoder_rug,21368832,1873
Oh well… we can just get rid of big ints anyway, and we’re going to do that soon.
Iterating bytes of str instead of chars
This one I was skeptical about when it was suggested to me on Reddit, as I thought that because Rust represents Strings using UTF-8, the cost of iterating over chars() instead of bytes() should be none.
But I decided to try anyway as it’s a small change.
I reverted the changes from the previous two sections as they were fruitless.
===> ./phone_encoder_mutable_vec
Proc,Memory(bytes),Time(ms)
./phone_encoder_mutable_vec,24612864,117
./phone_encoder_mutable_vec,24612864,177
./phone_encoder_mutable_vec,24608768,463
./phone_encoder_mutable_vec,24608768,818
./phone_encoder_mutable_vec,24649728,1515
===> ./phone_encoder
Proc,Memory(bytes),Time(ms)
./phone_encoder,24600576,106
./phone_encoder,24600576,174
./phone_encoder,24612864,453
./phone_encoder,24600576,792
./phone_encoder,24584192,1477
The results show that it in fact improved performance, if only by around 3%. Perhaps too close to call, so I also ran a Criterion benchmark (to run that, use cargo bench, then change the chars() call to bytes() and run cargo bench again).
Changing from chars() to bytes() when iterating over an ASCII String seems to make iteration twice as fast!
str_iter/50 time: [165.91 ns 167.19 ns 168.66 ns]
thrpt: [296.45 Melem/s 299.05 Melem/s 301.36 Melem/s]
change:
time: [-57.502% -56.952% -56.335%] (p = 0.00 < 0.05)
thrpt: [+129.01% +132.30% +135.30%]
Performance has improved.
Found 4 outliers among 100 measurements (4.00%)
2 (2.00%) high mild
2 (2.00%) high severe
Not so noticeable on my macro benchmark because the effect of other things drown this, but interesting nevertheless if you have a problem where you happen to have only ASCII input and you need to parse strings character by character.
Using a Vec of bytes instead of BigUint
In the Going the extra mile section of the first part of this series, the implementation that was benchmarked replaced BigUint with a Vec<u8>. That was possible because the problem didn’t really require numeric computations, just a way to uniquely identify each letter of a word in a way that could be mapped to phone number digits.
I re-implemented that idea on top of the changes from the previous section and ran my benchmark again:
===> ./phone_encoder_iterate_bytes
Proc,Memory(bytes),Time(ms)
./phone_encoder_iterate_bytes,24596480,
./phone_encoder_iterate_bytes,24600576,179
./phone_encoder_iterate_bytes,24604672,471
./phone_encoder_iterate_bytes,24616960,813
./phone_encoder_iterate_bytes,24608768,1522
===> ./phone_encoder
Proc,Memory(bytes),Time(ms)
./phone_encoder,23543808,102
./phone_encoder,23560192,165
./phone_encoder,23572480,432
./phone_encoder,23564288,760
./phone_encoder,23576576,1416
That means another 7% improvement, not as huge as I’d expected based, but still something to be proud of.
As an “honorable mention”, an Australian guy went to the effort of re-writing a similar version of the code I had at this stage, but he removed recursion! That’s no easy feat, and it does run almost 30% faster, so have a look at what it takes if you’re interested!
Using packed bytes for more efficient storage
Vec is extremely performant in most cases, but it does require allocations on the heap, which is costly compared to the time it takes to execute a few CPU instructions.
For this reason, and depending on the problem, manipulating bytes to “pack” information in a more optimal way may be a much more performant alternative.
I decided to implement an algorithm to encode digits as bytes in a way such that two digits could be encoded in a single byte. This means that with the maximum phone length of 50 characters (or bytes, because words and numbers are ASCII-encoded, and ASCII characters are represented as single bytes), I would only need 25 bytes to represent any number.
That should be much more performant than big-int arithmetics.
Here’s how it works.
As you might know, numbers are represented as bytes (normally 8-bit words) in a computer:
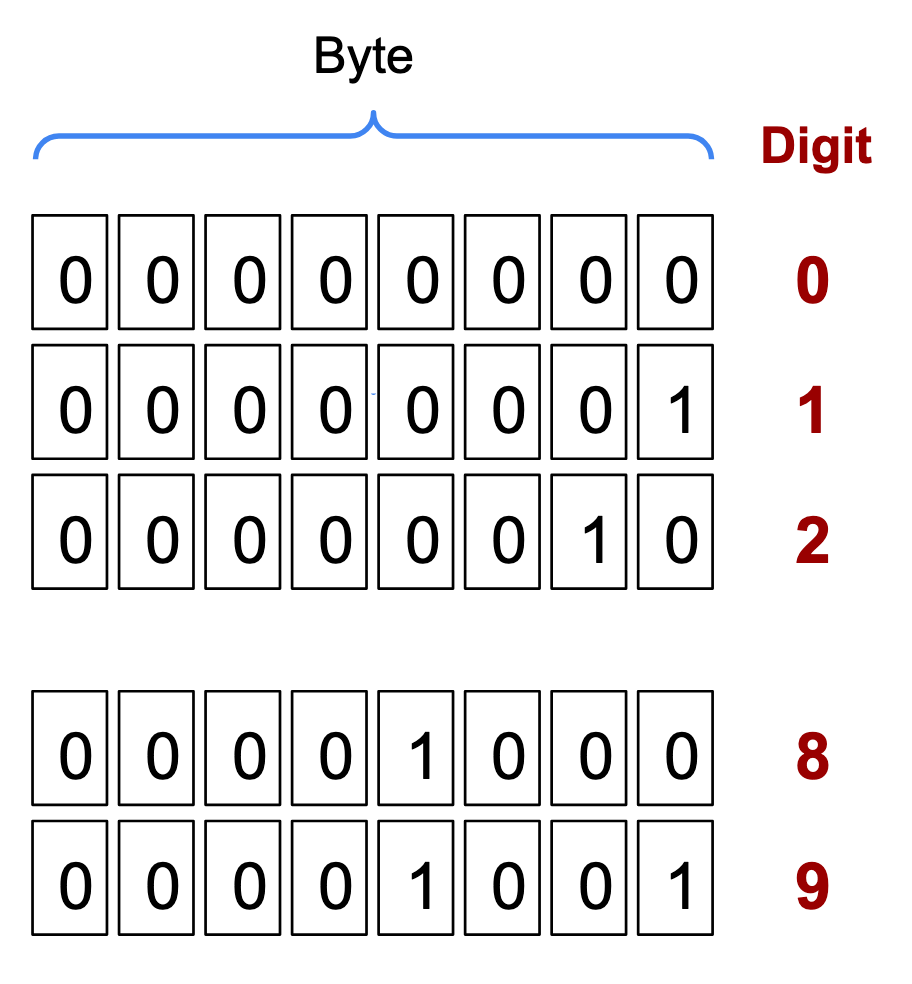
As you can see, if all we care about are digits from 0 to 9, this is wasting a whole lot of space as we only need 4 bits for each digit.
So, how can we pack them more compactly so that all of the bits are used?
Simple, we take two digits, shift-left one of them by four, then add them together:
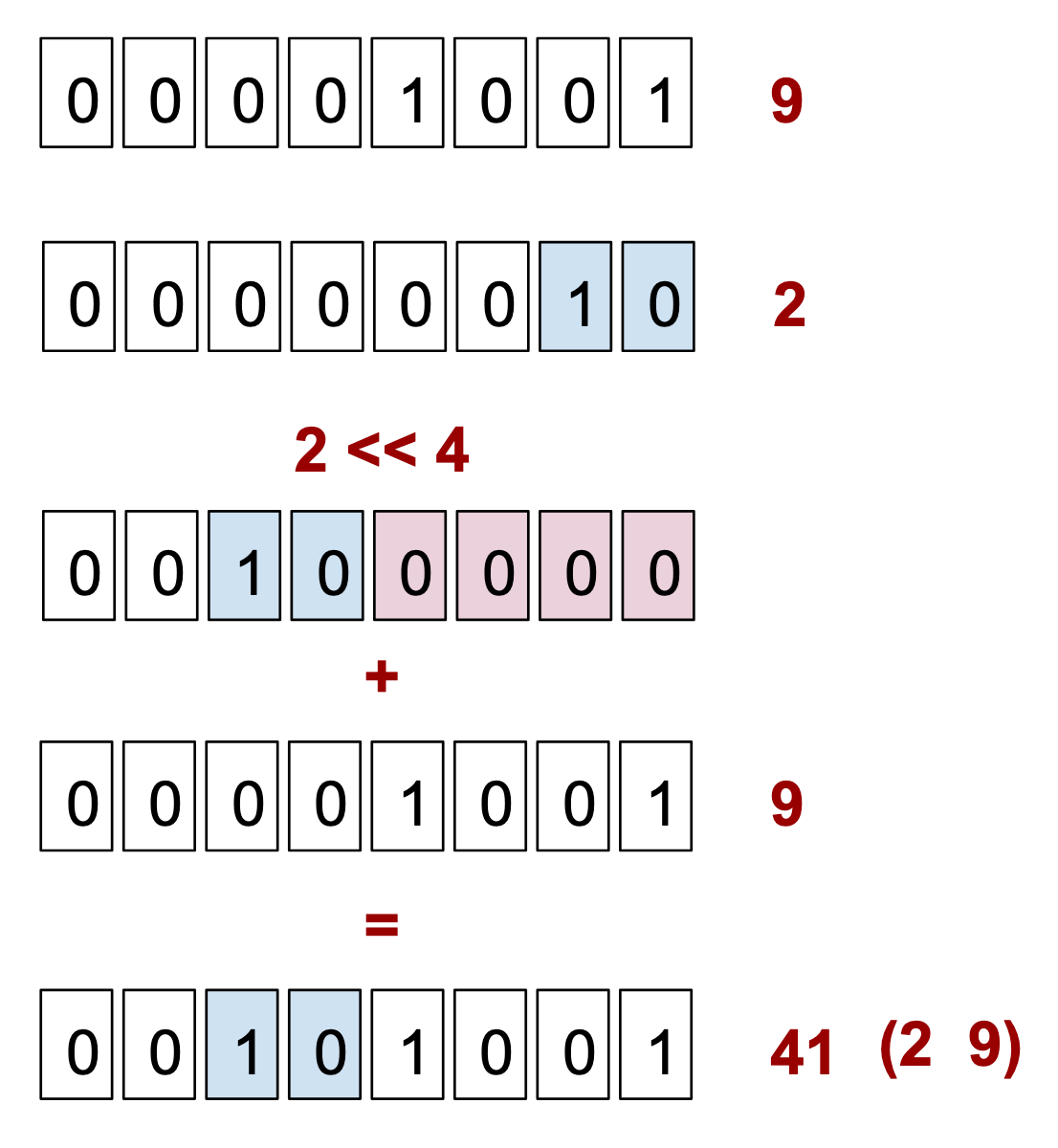
This works because binary addition is equivalent to the OR operation on two bytes when there’s no overlapping 1 bits (and hence nothing to carry-over), as is the case when each of the 4-bits of a byte are used to represent a single digit from 0 to 9. Because of that, we could’ve used either (2 << 4) + 9 or (2 << 4) ^ 9.
Now, to use an array of u8 as a key on a HashMap requires some work unless we don’t mind the full array being compared with the other arrays every time we look up something.
But if we use an array of 25 elements and we know that the large majority of items will require way fewer bytes to represent (assuming an average word has 6 bytes, for example, we would only need 3 bytes for its key based on digits), we end up doing much more work than necessary.
HashMap requires its keys to be Sized, hence we can’t use slices as keys. What we can do instead is create a struct that keeps track of the array and a length.
The struct will look like this:
#[derive(Debug, Eq, Clone)]
pub struct DigitBytes {
even: bool,
full: bool,
write_index: usize,
bytes: [u8; 25],
}
The even flag alternates between true and false for each byte written,
write_index keeps track of the current array index being written to (which only changes every second byte), and full is a mark that is required because the write_index is not enough to know if the last byte we can insert should fail or not.
We need to implement PartialEq and
Hash for the struct to be usable as a HashMap key. You can see the full diff with the previous version here (notice that there was almost no code changes in the actual algorithm, only the new data structure with some unit tests as this kind of thing is very easy to get wrong).
The results speak for themselves:
Proc,Memory(bytes),Time(ms)
./phone_encoder_vec_keys,23560192,107
./phone_encoder_vec_keys,23572480,172
./phone_encoder_vec_keys,23547904,443
./phone_encoder_vec_keys,23560192,764
./phone_encoder_vec_keys,23568384,1419
===> ./phone_encoder
Proc,Memory(bytes),Time(ms)
./phone_encoder,26415104,80
./phone_encoder,26431488,137
./phone_encoder,26451968,363
./phone_encoder,26456064,668
./phone_encoder,26435584,1262
This new version gives us a nearly 20% increase in performance.
Instead of using a [u8;25], notice that we could have used something like a [u128; 2] to hold the key data. I actually tried that as well, but it turns out this is slower, probably because more bytes need to be compared when keys are compared.
Using a faster hash function
I mentioned this in my previous post, but I thought this post, which is all about performance, should also briefly mention that if you use HashMap in circumstances where performance is a high priority,
you should consider swapping the default hasher for something else because the default one is DoS-resistant, which comes at the cost of performance.
Using a faster hashing function like ahash significantly improves the performance of map lookups.
I ran again the benchmark after swapping to ahash, which took a couple of line changes, to confirm the effect it has:
===> ./phone_encoder_bytes_key
Proc,Memory(bytes),Time(ms)
./phone_encoder_bytes_key,26456064,86
./phone_encoder_bytes_key,26451968,147
./phone_encoder_bytes_key,26443776,379
./phone_encoder_bytes_key,26447872,685
./phone_encoder_bytes_key,26427392,1281
===> ./phone_encoder
Proc,Memory(bytes),Time(ms)
./phone_encoder,26419200,77
./phone_encoder,26427392,119
./phone_encoder,26447872,284
./phone_encoder,26451968,493
./phone_encoder,26451968,919
This confirms that even after optimising my algorithm, the choice of hashing function still makes a huge difference between 20% and 40%.
Bloom Filter and other probabilistic structures
This optimisation may be a little far-fetched for my particular problem, but might work in certain applications where the lookup might be too expensive, perhaps because it requires a network trip.
Basically, instead of holding all the data in a HashMap locally, which requires that your server has enough memory for that, you put your data on a database and, before checking whether there’s a match for a certain key, you ask a Bloom Filter whether the item exists first. This can be helpful because Bloom filters (and newer variants such as Cuckoo filters) are designed to be extremely space efficient, so that they can store a huge amount of data in very little space.
The catch is that, as probabilistic data structures, such filters cannot give answers with certainty, only with a usually high probability of correctness. For example, Bloom filters can only tell with certainty when an item is NOT in the set. If the item is in the set, it may return a false positive, so when that happens, you must look at the lookup table or database to be sure.
Just for fun, I actually wrote an implementation using one of the many Bloom filter crates available for Rust, in which the Bloom Filter was put in front of the HashMap, avoiding checking the HashMap if the filter reported it did not contain a certain key.
Not surprisingly, this was much slower than just using the HashMap. However, I thought I should mention this as in cases where data doesn’t fit fully in memory, this can help a lot.
In case you’re looking for an interesting data structure, or perhaps some tool that can help you in some particular niche application you need to work on, check out Awesome Rust, a curated list of awesome Rust tools and libraries that might come handy one day!
Profile Guided Optimisation
Profile Guided Optimisation (PGO) is a way for the compiler to get information about how a program is likely to be executed so that it can try to perform more specific optimisations based on that when it re-compiles the same program. It’s similar to how a JIT would optimise machine code based on the actual program workload in languages that have one embedded in their runtimes, but with Rust, that information is first collected on a “training” run using an instrumented binary, then fed back to the compiler for re-compilation, so that it won’t incur a penalty at runtime.
I gave that a go and re-compiled the previous binary I had after enabling PGO. Here’s the script I used to re-compile:
#!/usr/bin/env bash
set -e
export PATH="$PATH:~/.rustup/toolchains/stable-x86_64-apple-darwin/lib/rustlib/x86_64-apple-darwin/bin"
PROGRAM="phone_encoder"
# STEP 0: Make sure there is no left-over profiling data from previous runs
rm -rf /tmp/pgo-data || true
# STEP 1: Build the instrumented binaries
RUSTFLAGS="-Cprofile-generate=/tmp/pgo-data" \
cargo build --release
# STEP 2: Run the instrumented binaries with some typical data
./target/release/$PROGRAM ../../../dictionary.txt ../../../phones_50_000.txt > /dev/null
./target/release/$PROGRAM ../../../dictionary.txt ../../../phones_100_000_with_empty.txt > /dev/null
./target/release/$PROGRAM ../../../dictionary.txt ../../../phones_200_000_with_empty.txt > /dev/null
# STEP 3: Merge the `.profraw` files into a `.profdata` file
llvm-profdata merge -o /tmp/pgo-data/merged.profdata /tmp/pgo-data
# STEP 4: Use the `.profdata` file for guiding optimizations
RUSTFLAGS="-Cprofile-use=/tmp/pgo-data/merged.profdata" \
cargo build --release
I now ran my benchmark again without re-compiling the Rust binary (to not undo the PGO work):
Notice that the benchmark generates new random input every time it runs, so the “warmup” runs had similar, but not the same inputs.
===> ./phone_encoder_ahash
Proc,Memory(bytes),Time(ms)
./phone_encoder_ahash,26423296,78
./phone_encoder_ahash,26451968,112
./phone_encoder_ahash,26456064,256
./phone_encoder_ahash,26464256,450
./phone_encoder_ahash,26460160,833
===> ./phone_encoder
Proc,Memory(bytes),Time(ms)
./phone_encoder,26415104,73
./phone_encoder,26456064,102
./phone_encoder,26460160,250
./phone_encoder,26456064,431
./phone_encoder,26460160,794
Nice! Just by re-compiling with PGO, without having to make any code changes, we get yet another 5% improvement in performance.
Flamegraphs
Another tool available to Rust developers to find out hotspots in their applications that require optimisations is flamegraphs.
With all the tools you need installed, you just need to run:
cargo flamegraph -- my-command --my-arg my-value -m -f
To get a nice flamegraph, as I did previously to get this one:

See a list of more profilers here.
Codegen Options
If you really need performance, you might want to look at Rust’s codegen options.
I am not familiar myself with what each option does, but a few ones to try might be these ones:
[profile.release]
lto = "fat"
panic = "abort"
opt-level = 3
lto = "fat" attempts to perform optimizations across all crates within the dependency graph.
panic = "abort" is a change of the default for the release profile, which is unwind.
opt-level is already 3 by default in the release profile, but I thought I should mention that you can actually set that to values between 0 and 3.
These made no difference on my benchmarks, though.
See the defaults for all profiles in the Rust Book, and more explanation about these options in the Rust perf-book.
Conclusion
I felt guilty for publishing an article in which I showed how Rust code did not automatically run faster than other languages (which resulted in my two posts titled How to write really slow Rust code)… that may be true, but it’s important to acknowledge that, on the other hand, Rust allows you to make your code just about as fast, if not faster, than pretty much any other language as long as you put in the time to learn it properly and pay some attention to your application algorithms.
That’s why I decided to try and redeem myself, at least a little bit, by helping other Rust developers to make their applications faster!
I hope that at least some of the advice in this post are useful to you and that you don’t need to learn the hard way, like I did, how to make your Rust code run faster.
If you still want more, perhaps try achieving warp speed with Rust, and don’t forget to go through The Rust Performance Book!