Revisiting Prechelt’s paper and follow-ups comparing Java, Lisp, C/C++ and scripting languages
In 1999, Lutz Prechelt published a seminal article on the COMMUNICATIONS OF THE ACM (October 1999/Vol. 42, No. 10)
called Comparing Java vs. C/C++ Efficiency Differences to Interpersonal Differences,
henceforth Java VS C, which seems to have later (March 2000) been expanded into a full paper, An empirical comparison of C, C++, Java, Perl, Python, Rexx, and Tcl for a search/string-processing program,
henceforth Scripting VS Java/C.
In that paper, they analysed data from a study (which was run for another paper, as we’ll see later) where participants were asked to solve a problem consisting of encoding phone numbers into a combination of digits and words from a dictionary, presumably to make it easier for humans to remember phone numbers they might want to recall later (this was in a time before mobile phones were widespread).
The same problem was later used by Ron Garret (aka Erann Gat) in his short paper, Lisp as an alternative to Java, henceforth Lisp VS Java, from the year 2000.
Both papers have been widely cited and continue to be linked to even today.
In this article, I would like to revisit these papers, analyse their methodology and conclusions, and try to find out whether anything has changed in the 21 years since those articles were published by writing my own solutions to the problem as if I, myself, had participated in one of the studies.
I wrote a solution in Java without looking into any other solutions in order to find out how my solution (and Java 16) would’ve done if it had participated.
After that, I analysed some other solutions and compared them against mine. Based on my findings and some comments by Prechelt himself in his paper, I decided to write a second Java program to match a completely different strategy that was commonly used in the more dynamic languages. I implemented the same algorithm also in Rust in order to get an idea of how a very modern systems-language would do.
That should allow us to compare modern languages more directly by using the same exact algorithm (to the extent possible), eliminating the potentially big differences that could arise from the different algorithms chosen by the programmer.
Overview of the studies
All data used in Prechelt’s Java VS C, as well as the Java/C/C++ solutions used in Scripting VS Java/C, come from an earlier study on a software development technique called PSP (Personal Software Process). This study actually ran between August 1996 and October 1998!
That means that some participants were actually using the very first release of the JDK!
The objective of that study had nothing to do with studying the differences between Java and C/C++, it was about investigating how effective PSP was (the results indicated that, mostly, PSP practictioners had more predictable, stable performance but also worked a bit slower).
55 graduate students participated in that study, 24 of which used Java, 9 used C, 13 used C++, and the other two used Modula-2 and something called Sather-K! Most students came from either the PSP course or a Java Advanced Course.
Nevertheless, this was the data the Java VS C paper was based on. It included 24 programs written in Java, 11 in C++ and 5 in C.
The instructions given to participants of the study, slightly adapted for the Lisp VS Java article, can be found at flownet.com.
Here’s a short description of the problem the participants had to solve:
All programs implement the same functionality, namely a conversion of telephone numbers into word strings.
...
The conversion is defined by a fixed mapping of characters to digits as follows:
e j n q r w x d s y f t a m c i v b k u l o p g h z
0 1 1 1 2 2 2 3 3 3 4 4 5 5 6 6 6 7 7 7 8 8 8 9 9 9
The task of the program is to find a sequence of words such that the sequence of characters
in these words exactly corresponds to the sequence of digits in the phone number.
All possible solutions must be found and printed.
The solutions are created word by word and if no word from the dictionary can be inserted at some point
during that process, a single digit from the phone number can appear in the result at that position.
Many phone numbers have no solution at all.
If you would like to “participate” in the study, follow the instructions given in this link as closely as possible. You can then compare your solution against mine and other’s using my GitHub repository which has instructions on how to easily add your solution to the current benchmark and run it!
This is a nice problem, not too easy, but not very hard either. I found it interesting enough to want to participate myself after I randomly stumbled upon it on the internet, 21 years after the study was published!
Apparently, I was not the only one. Ron Garret (who worked at Nasa at the time and later went to work at early Google) found it interesting enough to run his own study (the already mentioned Lisp VS Java one), re-using the same problem but asking only Lisp programmers to solve it. He got 16 solutions from volunteers recruited from an Internet newsgroup.
Even Peter Norvig, who I consider a Computer Science celebrity, posted his own solution to the problem, written in Common Lisp, on his website.
What did they all find out?
Well, basically, that Java is slow, uses too much memory and that it takes at least as much effort as C or C++ to write something using it. Also, at least in Prechalt’s case, that the difference between programmers is generally greater than the difference between languages.
In their own words:
Java VS C
As of JDK 1.2, Java programs are typically much slower than programs written in C or C++.
They also consume much more memory.
But also:
However, even within one language the interpersonal differences between implementations
of the same program written by different programmers (bad/good ratio) are much larger
than the average difference between Java and C/C++.
Scripting VS Java/C
... for the given programming problem, “scripting languages” (Perl, Python, Rexx, Tcl)
are more productive than conventional languages.
In terms of run time and memory consumption, they often turn out better than Java and
not much worse than C or C++.
And again:
In general, the differences between languages tend to be smaller than the typical differences
due to different programmers within the same language.
Lisp VS Java
... Lisp’s performance is comparable to or better than C++ in execution speed ...
it also has significantly lower variability, which translates into reduced project risk.
Furthermore, development time is significantly lower and less variable than either C++ or Java.
Memory consumption is comparable to Java...
Analysis of the experiments and their conclusions
Prechelt describes in detail the setup of his experiments and the profile of participants, as well as the many caveats involved in each study. I highly recommend skimming through the PSP paper that kicked off his later publications.
Notice that there were two different groups of students in the original study: PSP students, who had learned how to use a technique (PSP) to explicitly increase the quality of their work, and the control group, mostly students from a Java course who were obliged to participate in the study. Most of the C/C++ submissions originated from the PSP group (17 VS 5), but the Java submissions were more evenly divided (14 VS 10).
It’s important to remember that PSP students had been conditioned to spend more time analysing the problem and attempting to prevent defects in their programs, and that the most important requirement of the study was for programs to be as reliable as possible.
This implies some difference in the types of students working in Java VS C/C++. In Java VS C, Prechalt even mentions that on average, the Java programmers had only half as much programming experience in Java as the C/C++ programmers had in C/C++, which is natural given that the study ran when Java had just barely been released for the first time.
Anyway, in both the PSP paper and Java VS C, Prechelt was very sincere about the limitations of the study and his conclusions were pretty solid given the data (and the fact they were using Java 1.2, released in 1998).
However, things get murkier with Scripting VS Java/C. Notice that Prechelt uses the same data again for the Java and C/C++ programs, but for the group of scripting languages, the participants were basically random people found on early internet groups:
The Perl, Python, Rexx, and Tcl programs were all submitted in late 1999 by volunteers after I had posted a
“Call for Programs” on several Usenet newsgroups (comp.lang.perl.misc, de.comp.lang.perl.misc, comp.lang.rexx,
comp.lang.tcl, comp.lang.tcl.announce, comp.lang.python, comp.lang.python.announce) and one mailing list
(called “Fun with Perl”, fwp@technofile.org).
Notice also that the time taken to solve the solutions was self-reported and the script language participants were not monitored in any way, quite unlike those who took part in the first study (many of whom had been conditioned to spend more time thinking about the problem, as PSP encouraged).
Prechelt mentions that the work times reported by the script programmers may be inaccurate. Well, this is probably the biggest understatement in all of his papers.
The paper finds that the scripts’ median time was 3.1 hours, compared to 10.0 hours for the non-script group.
Notice that depending on how you look at the data, you could also have concluded that the participants who self-reported their times were 3 times faster than those who were actually monitored. More than half of the students in the original PSP study spent more than a working day on the problem, and they were not only using Java in that study, but basically whatever language they wanted to use (though Prechelt seems to have only used the Java results in his later paper)!
There’s some more interesting findings, though. For example, the fact that scripts were two to three times shorter than non-scripts, and that there’s conflicting results regarding differences in the reliability of programs, a finding that has been puzzling many other study’s authors, specially in the area of static VS dynamically typed languages (as that suggests that using static types do not actually result in more reliable programs).
If Prechelt was mostly forthcoming in pointing out caveats to his findings, Garret was much less so.
It’s unclear how the data was collected for his study as the procedure was not described at all apart from a note saying that to the extent possible we duplicated the circumstances of the original study. Given that the participants were recruited from internet groups, I doubt that the subjects were monitored in place, which makes me think that the Development time data collected should be taken with a giant grain of salt. However, the reported times do seem similar to the scripting group self-reported times in Prechelt’s study: 2 to 8.5 hours for Lisp users, 3 to 10 for the scripting group in Prechelt’s study.
Prechelt makes an interesting observation regarding that:
... an old rule of thumb, which says that programmer productivity measured in
lines of code per hour (LOC/hour) is roughly independent of the programming language.
He uses that reasoning to conclude that, if that’s true, the self-reported times should not be far from reality.
Anyway, Garret goes much further and claims in his conclusion:
Lisp is superior to Java and comparable to C++ in runtime, and it is superior
to both in programming effort and variability of results.
That’s quite a strong conclusion.
He asks himself in his paper:
why, if Lisp is so great, is it not more widely used?
Based on a small study like Garret’s, I find that the premise that Lisp is so great is unwarranted. Sure, he may
be using his own experience and perhaps others’ testimonies to take that as a fact, but in a paper like that, you must
provide your sources when making swiping statements such as this one. Personal feeling is not good enough.
However, the data does suggest that Lisp is about as productive as the scripting languages of the day and has a speed comparable to C and C++, which is indeed a remarkable achievement.
My own experience solving the phone number problem
I came across Prechelt’s phone number problem when reading an article about Julia in which the author said:
My heart was broken because Common Lisp is such a fine fine language
and it is a joy to work in and hardly anyone uses it in industry.
The industry has a lot of code in Java even when it takes **much less time** to write code in Lisp.
What happened to the programmer’s time is more important than the machine’s?
The source for such statement was Garret’s Lisp VS Java. I was fascinated by the conclusion of that paper when I first read it, so I decided to “participate” in the study to see if their conclusions had been realistic and if, perhaps, Java 16 (latest version as of writing) improved at least a little bit compared to the greatness of Common Lisp.
I read the instructions linked from Garret’s paper and immediately started working on it.
What follows is a brain dump I wrote just as I finished my solution.
Working on the problem
I managed to write all the boilerplate code (read input, clean it up, collect and print results, basic tests) in just about 1 hour. Meanwhile, I was deciding the best strategy to make the solution efficient and decided to use a Trie data structure, which was already familiar to me.
It took me another hour or so to write a basic solution to the problem with a few more tests based on the examples given in the instructions… but actually finishing the algorithm off, unfortunately, took me some more time (I don’t write algorithms like that every day), specially because of a small bug that I couldn’t easily figure out how to fix (I was trying to inject a digit when I could not find a word on any position, instead of only at the beginning of a potential word… once the reason was found, it was trivial to fix).
Time
All in all, I estimate my total time was around 3.5 hours. That’s almost twice as much as Norvig, but at least I can take some comfort in knowing I managed to do quite well when compared with other participants in the study (again, those who were actually monitored, and did not just self-report): 3 to 25 hours for C/C++, 4 to 63 hours for Java.
The non-monitored participants reported between 2 to 8.5 hours for Lisp, and around 1 to 10 hours for the scripting languages.
Lines of code
My solution required 167 lines of code using Java 16, compared with a range of 51 to 182 for Lisp, 107 to 500+ for Java, 130 to 500+ for C/C++, around 50 to 200 for the scripting languages.
Performance
To measure performance, I downloaded a few files from this page, including dictionary.txt, input.txt and output.txt.
Because computers have come a long way in the last 21 years, the original input file and dictionary were far too small to make the programs run for more than a second! So I had to generate some longer inputs in order to get a better sense of how performant my solution was.
Given that none of the studies seem to have published the solutions they collected, I used Peter Norvig’s CL implementation as the baseline.
In Lisp VS Java, most Common Lisp solutions had very similar speed and memory usage, so I assume Norvig’s implementation would also be close to the others.
You can read the full instructions to run the test yourself on this GitHub Repository, which includes my solution, several others I found around the internet, besides the ports I did of Norvig’s solution to Java and Rust.
The results of this analysis will be shown in the next section after we discuss the different strategies that can be used to solve the problem.
Comparing solution strategies
Prechelt noticed that there were basically two main approaches in the solutions he analyzed:
Most of the programmers in the script group used the associative arrays provided
by their language and stored the dictionary words to be retrieved by their number
encodings.
The search algorithm simply attempts to retrieve from this array, using prefixes
of increasing length of the remaining rest of the current phone number as the key.
Any match found leads to a new partial solution to be completed later.
In contrast, essentially all of the non-script programmers chose either of the following
solutions.
In the simple case, they simply store the whole dictionary in an array, usually in both
the original character form and the corresponding phone number representation.
They then select and test one tenth of the whole dictionary for each digit of the phone
number to be encoded, using only the first digit as a key to constrain the search space.
This leads to a simple, but inefficient solution.
The more elaborate case uses a 10-ary tree in which each node represents a certain digit,
nodes at height n representing the n-th character of a word.
A word is stored at a node if the path from the root to this node represents the number
encoding of the word.
This is the most efficient solution, but it requires a comparatively large number of
statements to implement the tree construction.
This analysis is spot on in my opinion! My solution turned out to be the one he called the most efficient one (he’s describing a Trie data structure), Norvig’s solution was exactly the one most of the script group came up with, which was easier to implement.
This difference in strategy has obvious consequences to the length of each program, as well as its efficiency. So when we compare programs that use widely different strategies, we cannot really extrapolate our conclusions to differences in the languages being used. In other words, programs that used the trie strategy (most of the non-scripting ones) are going to be longer than the ones that used associative arrays (most of the scripting ones) regardless of the language used.
However, it is still quite interesting to note that the language seems to somehow guide programmers to use one or another strategy.
Benchmarks
To see what would’ve happened if I had chosen Norvig’s strategy instead of using a Trie, I decided to port his CL code as closely as possible to Java.
I did the same thing targeting Rust as well in order to get a baseline for how fast the algorithm could go (or so I thought).
You can see the source code for each implementation on GitHub:
- Java 1 - my original trie-based implementation.
- Java 2 - port of Norvig’s solution to Java.
- Lisp - Norvig’s solution written in Common Lisp.
- Rust - port of Norvig’s solution to Rust.
UPDATE (25th July 2021): I’ve now added solutions in Dart and Julia as well! See the
Incl. DartandIncl. Juliatabs in the results linked just below to see how they performed.
The results (click here to see the full data and more charts):

Notes:
Java 1implements a different algorithm (a Trie, not an associative map) than the other implementations.Rustuses two libraries (num-bigintandlazy_static), the other solutions use none.

Notes:
- Java and Lisp allocate memory greedly due to being garbage-collected, unlike Rust.
- Running Java with flags to limit memory usage brings Java results down somewhat, but not much.
See
Third runson the results spreadsheet to see how the Java results change.

Notes:
- The Rust solution gets very slow with a higher number of inputs. I asked Rust developers on the Rust Discord Channel for help figuring out why it was so slow, but after several suggestions, the results did not improve significantly (the result shown above includes some suggestions). I even generated a flamegraph to profile the Rust code, but was unable to find any quick fix.
{kind=link}
EDIT (2021-07-31): the Rust code I wrote for this benchmark has several issues, which I decided to discuss at length in my next blog post!
Please consider reading that article once you’re done reading this one :).
If you don’t have time: Rust can run much faster, but so can the other languages, and it turns out that the Java implementation might run faster than the Rust fastest implementation, according to the new benchmarks I’ve run after many Rust developers came to assist in making Rust faster. Common Lisp may have fallen behind, but that’s likely just because it was not nearly as optimised as the Java and Rust implementations were.
Quite unexpectedly, Common Lisp was the best language overall, running the fastest with all but the largest input size (and even then, it was beaten only by a different algorithm implemented in Java) and consuming very little memory.
Java still appears to consume much more memory than low-level languages (Rust in this case) and, these days, even than Common Lisp (see my remarks above about tweaking the JVM memory settings, which don’t really help). On the other hand, it can be very fast.
The Rust solution shows how little memory can be necessary to run through any number of inputs (the memory is the same for any input size, which is expected as most of the memory is taken up by loading the dictionary), but has some unfortunate performance degradation with an increased number of inputs (see notes above).
This seems to indicate that even when speed is of the essence, using Rust may not give automatic wins.
Language comparison
The Java port (Java 2)
has 99 LOC VS 74 LOC for the original CL.
Most of the extra lines in Java are actually from a couple of functions I had to implement by hand:
<T> List<T> append( List<T> list, T item )- needed in order to recurse under each arm of the Trie without affecting the current, partial solution.char[] removeIfNotLetterOrDigit( char[] chars )- CL has a nice way of doing this by combining existing functions.
These two functions took 19 lines, so if we discount them, the Java LOC goes down to 80 lines, very close to the Lisp
solution! Notice also that Lisp programmers like to close blocks on the same line. If we did the same in Java, moving
all } into the previous line, we could remove another 23 lines, bringing the Java solution to 57 LOC.
That’s not surprising when you look at the code (with comments removed):
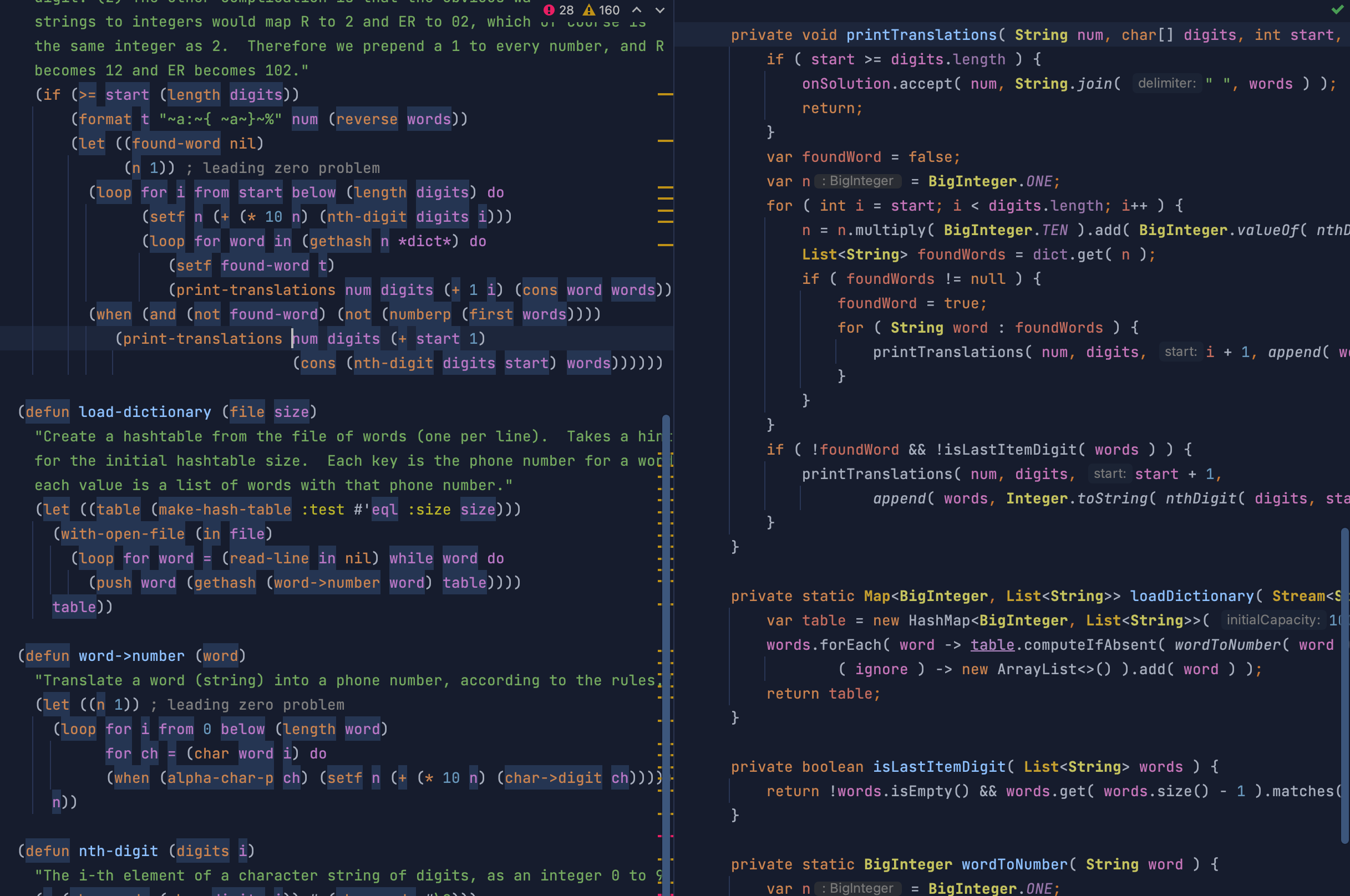
- Lisp
(defun print-translations (num digits &optional (start 0) (words nil))
(if (>= start (length digits))
(format t "~a:~{ ~a~}~%" num (reverse words))
(let ((found-word nil)
(n 1)) ; leading zero problem
(loop for i from start below (length digits) do
(setf n (+ (* 10 n) (nth-digit digits i)))
(loop for word in (gethash n *dict*) do
(setf found-word t)
(print-translations num digits (+ 1 i) (cons word words))))
(when (and (not found-word) (not (numberp (first words))))
(print-translations num digits (+ start 1)
(cons (nth-digit digits start) words))))))
- Java
private void printTranslations( String num, char[] digits, int start, List<String> words, BiConsumer<String, String> onSolution ) {
if ( start >= digits.length ) {
onSolution.accept( num, String.join( " ", words ) );
return;
}
var foundWord = false;
var n = BigInteger.ONE;
for ( int i = start; i < digits.length; i++ ) {
n = n.multiply( BigInteger.TEN ).add( BigInteger.valueOf( nthDigit( digits, i ) ) );
List<String> foundWords = dict.get( n );
if ( foundWords != null ) {
foundWord = true;
for ( String word : foundWords ) {
printTranslations( num, digits, i + 1, append( words, word ), onSolution );
}
}
}
if ( !foundWord && !isLastItemDigit( words ) ) {
printTranslations( num, digits, start + 1,
append( words, Integer.toString( nthDigit( digits, start ) ) ), onSolution );
}
}
Java is definitely more awkward, but not really very different.
I am not mentioning this to make Java look better than it is, but to show how LOC measurements can be misleading and how Java has actually come a long way since 1998.
The Rust port required 116 LOC (though it had to use libraries for things the other languages have in their standard libraries), which is not bad for a lower level language.
For comparison with the Java and Lisp code shown above, here’s the most important function in the Rust solution:
fn print_translations(
num: &str,
digits: &Vec<char>,
start: usize,
words: Vec<&String>,
dict: &Dictionary,
) -> io::Result<()> {
if start >= digits.len() {
print_solution(num, &words);
return Ok(());
}
let mut n = ONE.clone();
let mut found_word = false;
for i in start..digits.len() {
n = &n * (&*TEN) + &nth_digit(digits, i);
if let Some(found_words) = dict.get(&n) {
for word in found_words {
found_word = true;
let mut partial_solution = words.clone();
partial_solution.push(word);
print_translations(num, digits, i + 1, partial_solution, dict)?;
}
}
}
if !found_word && !words.last().map(|w| is_digit(w)).unwrap_or(false) {
let mut partial_solution = words.clone();
let digit = nth_digit(digits, start).to_string();
partial_solution.push(&digit);
print_translations(num, digits, start + 1, partial_solution, dict)
} else {
Ok(())
}
}
The Rust code is less noisy than Java, mostly due to type inference and operator overloading, but otherwise it’s also not very different from either Lisp or Java, discounting unimportant syntax differences.
Interestingly, the CL program runs faster than either Java or Rust and consumes much less memory than Java, and not much more than Rust!
The Rust solution’s performance seems to scale very badly with the number of inputs. I am not a Rust expert, so unfortunately I could not pinpoint what’s going on there (I did try to improve it without success), but my suspicion is that the
num-bigintcrate is not implementingBigUintas efficiently as Java and Lisp do.
Conclusion
Regarding the studies reviewed in this article, I think it’s fair to conclude the following:
Java VS C
- it was a great paper in general.
- good discussions about its own weaknesses.
- its conclusions were generally accurate but reflect the state of things in 1999.
- Java programs are typically much slower than C and C++ seems to not be accurate today, at least if we accept that the Rust results would be comparable to C and C++.
Future work should definitely include C and C++ in the comparison, and implement the Trie approach also in those languages as perhaps Rust cannot always be used a proxy to C and C++ performance as I had assumed.
Scripting VS Java/C
- very weak results due to the different methodology with which the participants were selected and monitored.
- failed to sufficiently compensate for the fact that most of the Java and C/C++ participants were trained in a specific software development technique that biased their results.
- interesting observations regarding the LOC/time rate and how it tends to not vary between languages.
- its conclusion that program reliability does not vary significantly by language seems persuasive.
Lisp VS Java
- very strong claims that nevertheless appear to generally stand to scrutiny.
- lack of rigour when describing methodology significantly weakens the paper’s standing.
- the conclusion that Common Lisp has speed comparable to C/C++ (assuming Rust to be a good proxy) seems accurate, at least for Prechelt’s problem.
- the conclusion that it requires lower effort than Java is not nearly as strong as it was back in the year 2000.
Garret’s paper would probably have benefited from feeling less of a Lisp-chill and being more based on hard evidence, of which it did have some.
Final remarks
In general, I believe what we can take from this discussion is:
- LOC depends a lot on the specific algorithm used, so comparing languages based on all solutions combined is flawed.
- Language choice impacts the algorithms programmers tend to choose (indirectly amplifying language effects on program efficiency and effort required).
- The variance in amount of effort between programmers (specially due to their a priori knowledge and ability to choose appropriate solutions for a problem) far eclipses variance due to the language chosen.
Given all of the above, I think we have enough evidence to believe that the choice of a programming language has less impact than the papers discussed here appear to imply. Still, it does have a significant impact on many factors (e.g. Java is fast but requires a lot of memory, Rust does not automatically make everything faster but does decrease memory usage by a good margin, Lisp and scripting languages guide programmers to make use of higher level algorithms that are easier to implement and, at least in some cases, perform as well as lower level languages).
Choosing the appropriate algorithm to solve a problem will generally have much more impact in both efficiency and amount of effort required than using a particular language. Care must be taken, however, to avoid language choice guiding programmers towards the use of less efficient (or more time-consuming, depending on the priorities of a project) algorithms/patterns.
Languages with extensive libraries might help both by providing out-of-the-box algorithm implementations
(e.g. a ready-to-use Trie) that are highly efficient and require no effort by the programmer to use,
and by avoiding programmers having to even make decisions about algorithms in the first place (e.g. by providing a solution to a
higher level problem that might use different algorithms/implementations under the hood, unbeknownst to the programmer
using it, like sorting functions).
This might actually partially explain why Lisp never became mainstream (it makes libraries less necessary, but that backfires in some cases where a library could’ve solved the problem better and faster than what the Lisp programmer would’ve come up with), but a language like JavaScript, which has been heavily focused on library sharing, did (ignoring the heads-up it has had due to being the only choice in front-end web development for a long time).
Finally, when choosing a language at a larger company where many developers must work on the same code base, the factors considered in the discussed papers and in this article may be much less relevant than the factors impacting the ability of the language to facilitate large scale code bases.
Therefore, choosing a programming language requires taking into consideration not only factors such as its speed, single developer effort and its resource usage (the factors discussed here) but also things like its type system (which may help reason about code or just make everything too hard to change), modularity (separation of concerns), simplicity (code is easier to read when it’s simple), expression power (more concise code can be a benefit or a curse) and so on.