A look at Unison: a revolutionary programming language

Unison is a pure functional programming language that comes with a few revolutionary ideas. Seriously, it makes everything we’re used to, like long builds, dependency version conflicts, tests that run every single build even when nothing checked by them has changed, manual encoding and serialization of data, and lots more look like primitive stuff from the time we were programming in caves. For this reason, I’ve been following Unison development excitedly, if quietly, for a few years now.
As I write this in early 2023, finally, I think it has reached a level of maturity where it’s actually usable for real work, so I decided to write about my impressions using the language for something non-trivial.
Could it really be the language of the future, as its website cheekily proclaims?! What’s so revolutionary about it? Why are we not using its revolutionary ideas in other languages yet if they are so great?!
Let’s have a closer look. It really is worth it!
Introduction to the big idea
The Unison website is very cool and has a full page dedicated to explaining the big idea behind Unison. So, I highly recommend reading that before you continue. Please come back after you’re done!
In their words, here it is:
Each Unison definition is identified by a hash of its syntax tree.
Put another way, Unison code is content-addressed.
Yes, that’s very concise and may not sound terribly interesting. But this simple idea enables things you probably didn’t even think were possible.
For example, Unison does away with builds. Completely! Have you been looking for a language that has great compile times while still being strongly typed? Well, how about a language with basically zero compilation time??
It sounds outrageous, I know… I also thought it was basically bs before looking into it in more detail. But, believe me, it’s not.
Code is not stored in multiple, seemingly unrelated text files in Unison. It’s stored in an actual database. One that you can only append to, similar to a Git repository.
The reason Unison doesn’t have builds is that code is already stored in its type-checked, AST (Abstract Syntax Tree) form in that database, linked to other definitions by its hash.
If you write the same function with different names, even with different variable names and perhaps declaring bindings in different order, for example, Unison will just store one function, but add an alias to it if you really want it. It has a canonical representation for all code, which allows it to do that.
Even documentation and types are stored this way, though you may use unique type to avoid identically structured types to be considered the same.
When you change the type of a function, it only impacts other code that uses it if you explicitly use Unison refactoring capabilities to update that function everywhere it’s used (we’ll see exactly how to do that later). It’s simply impossible to commit code that wouldn’t compile. You can choose to leave the old function alone and just bind the name to a new function, or rename the old one, that’s fine too! It’s your choice.
That means there’s no version conflicts either in Unison. You can have different functions using different versions of some other function at the same time. The different versions are different hashes, and functions only refer to the hash of other functions, so there’s never a conflict.
This idea also enables easy distributed computing, after all, sending a computation, code, data and all, to another machine, is much easier when you know exactly what the code dependencies of the computation are, what the data type definitions are, and are unique and cannot conflict.
This is not an original idea

Many readers may be interjecting that this idea is an old idea: Smalltalk already had the idea of an “image” where all source code was stored instead of text files.
Other readers may remember Joe Armstrong’s famous talk, The mess we’re in, where the idea of using (unspoofable) hashes instead of names to facilitate distributed computing, among other things, is expanded at around the 36:00 mark.
However, Unison may be the first time this idea has been implemented in such a way that the full benefits described in the previous section can be fully realized. Even if it’s not, I believe it’s still a wonderful implementation of that idea, specially when combined with pure, statically typed functional programming.
No IDE required
Even though an IDE is not required with Unison (in the sense that you can still do everything a professional developer must be able to do, like introspect the code, read docs, refactor, test, find references, everything without an IDE - unless you consider
ucmpractically an IDE 🙂), as this section will show, you can use one, of course. They are working on an LSP implementation for Unison, for example. Check the Editor Setup documentation for more on that.
I already mentioned how code can be refactored trivially with Unison. But notice that you don’t need an IDE or some other tool to do that. Unison has something called the Unison Codebase Manager (used via the ucm tool) which is used to manipulate the code base. That includes adding, changing, refactoring code.
Instead of just talking about it, it’s time to actually show how it all works… I will not explain the Unison language itself (check the Unison at a glance page for that)… if you know Haskell, it will look very familiar.
What’s really interesting is how you write Unison code. No IDE is required, just fire up your favourite text editor, as long as it has an integrated terminal, as you’ll need one!
I chose to use emacs. On one buffer (or “window” if you’re not an emacs user), fire up ucm (I found that using ucm from M-x shell works quite well):
On another buffer, in the same directory, create a .u file (use any name you want with the .u extension, it won’t matter)… that’s only used for you to write new code and watch expressions.
Keep both buffers visible at all times.
To start with, evaluate a couple of expressions, which is done by prepending the > character to them as shown below:
Notice that code and expressions are entered via the
.ufile, NOT on theucmterminal! TheucmCLI is not a REPL. This will become clear soon.
> list = [1, 2, 3]
> head list
> reverse list
Now, save the file with the above contents while looking at the ucm shell. It will look like this:
Looks very cool, but let’s see what happens when we make a mistake:
> sort [4, 2, 3, 1]
Result:
This shows how much attention the Unison developers have spent on giving good error messages.
It seems the problem is that sort is ambiguous so we must specify which one we mean to use. Notice how the error message says there’s a Heap.sort and a List.sort… so we can use one of them:
use base.data.List
> List.sort [4, 2, 3, 1]
Result:
That’s better, but what I am really interested in is real world code that does something useful, which means I need to use lots of IO!
That brings us to how we can use ucm to discover Unison functionality. By reading the Unison docs briefly, I know that there’s a type called IO, but not much else… so we can type find IO in ucm to see what is available… this being such a generic query, it will list a lot of things, but you should see this right in the beginning:
1. builtin type base.IO
That’s probably what we’re looking for. To confirm that, list the contents of base.IO with ls:
Lots of useful stuff in there. To know what some of it does, you can use docs:
Notice that you can refer to the number in the previously listed definitions instead of the full name. In other words,
docs 4above is the same asdocs base.IO.FilePath.
You can also use view to view the actual definition of a symbol.
If you type ui, it will open the full hyperlinked Unison documentation on a browser, in case you’re not a fan of browsing docs on a terminal!
Working with real Unison code
Before proceeding, as we will want to actually store code in the ucm database, we need to create a namespace and fork base into its lib namespace (where all dependencies of a project go).
By exploring the documentation, it was easy to find out how to read a text file line by line. But Unison doesn’t have a simple function to read the whole contents of the file, and Handle.getLine does not let us specify the encoding, it just uses the platform default encoding (but there’s a note in the docs that this will be fixed soon…).
So, let’s write a function to read the full contents of a file as UTF-8:
use base.IO.FilePath
use base.IO.FilePath.open
use base.IO.Handle
use base.IO.FilePath.FileMode.Read
readAllBytes path =
hdl = open (FilePath path) Read
finally '(Handle.close hdl) do
use Bytes ++
recur read =
if Handle.isEOF hdl then
Bytes.empty
else
!read ++ recur read
recur '(Handle.getSomeBytes hdl 4096)
readUtf8 = readAllBytes >> Text.fromUtf8
Result:
Notice how Unison has inferred the types of the functions without us having to explicitly write them! The
{IO, Exception}part means the function requires theIOandExceptionabilities.Abilities are another really cool idea in Unison which refer to effectful computations, or albebraic effects to use the academic term… unfortunately, including a proper discussion of abilities would make this post too long, but I do recommend reading about it in the Unison documentation later as it’s very interesting.
The readUtf8 function above uses the >> operator (read as andThen), one of the function application operators in Unison.
The others are <<, |> and <|. Both << and >> return functions, but <| and |> return values.
Also interesting is the ' quotation, which is a way to create a delayed computation.
If you try to run readUtf8 from the ucm, you’ll run into a problem.
This is a little annoying, only functions that take no arguments can be executed with run. Remember, ucm is NOT a REPL!
Also, watch expressions do not have the IO ability, so trying to execute an expression like this:
> unsafeRun! '(readUtf8 "hi.txt")
Results in an error:
To my knowledge, the only way to run functions that require IO and take arguments is to write a temporary main-like function that reads arguments from IO.getArgs.
Before we try that, let’s add the two functions we have already defined to the database:
Now, we can remove those definitions from the buffer, and add the temporary main function.
For example:
tempMain _ =
match head !getArgs with
Some file -> readUtf8 file
None -> "<no args provided>"
-- this is a comment
--- anything below this line is ignored because it starts with '---'.
-- this allows you to keep some definitions visible,
-- without constantly re-defining things.
This example shows the ! operator being used to invoke the no-args function, IO.getArgs. ! is basically the reverse of the ' quotation operator, i.e. to invoke a delayed computation of type 'a, like getArgs, you can do !getArgs. But notice that’s just equivalent to getArgs (), which is invoking getArgs with an empty argument list, but it avoids having to wrap it within parens everywhere.
Now, we can use run to invoke tempMain as it has the right signature:
It works! 🙌
But there are some things we need to fix in this program. First, if we compile and execute this program, it won’t actually print anything because tempMain returns the Text but doesn’t use it… we only see the result in ucm because it prints the result of the run call.
Second, when we try to read a file that does not exist, we get a Unison error report… it’s nice and all, but we probably wouldn’t want a real world application to do that.
For these reasons, let’s look at how we can handle errors in Unison and print to stdout/stderr.
Dealing with errors
Many programming languages look nice when working on pure code that just does math, but are terrible at helping the programmer deal with the mess of the real world - in other words, they are bad at error handling.
Let’s see how we can deal with the real world in Unison by ensuring that our main function handles errors. That’s hard because everything may fail at runtime, including things that most programming languages ignore, like printing to stdout.
Unison has many types/abilities that help with errors, like Throw, Exception, Failure and Abort.
Check the Error Handling Documentation for more details.
Here’s my initial, not so great attempt at writing something like cat in Unison, based on the previously added readUtf8 function and without letting main propagate any errors:
use lib.base.abilities.Throw
{{ Logs `message` to {stdErr}. Crashes the program if it cannot write. }}
logError! : Text ->{IO} ()
logError! message =
put msg = unsafeRun! '(putText stdErr msg)
put message
put "\n"
logFailure! failure =
logError! (Failure.message failure)
{{ Get the process arguments, returning the first argument.
If the number of arguments is not exactly 1, a {type Throw} occurs.
}}
singleArgOrFail : '{IO, Throw Text} Text
singleArgOrFail _ =
match catch getArgs with
Right (arg +: []) -> arg
Right _ ->
throw "A single arg must be provided."
Left failure ->
use Text ++
throw <| "Unable to read arguments due to: " ++ (message failure)
-- Takes an action that requires Exception ability and gets rid of that.
internal.errorHandler : (() ->{IO, Exception} ()) ->{IO} ()
internal.errorHandler action =
match catch action with
Left failure -> logFailure! failure
Right _ -> ()
-- no Exception ability, so `main` cannot exit with a stacktrace.
main : '{IO} ()
main _ =
internal.errorHandler do
file = Throw.toException (e -> failure e ()) singleArgOrFail
readUtf8 file |> printLine
This time, I decided to explicitly type most functions to ensure that they don’t accidentally get abilities I didn’t mean to add.
For exploration, I used both the Exception and the Throw abilities. Throw seems to be a slightly simplified Exception, but I am not sure that in this case, using it was much better… we will revisit that soon.
The important thing is that now, I can actually compile and run this program from the terminal instead of only from ucm! A real app, if you will!!
To create a compiled file with only the necessary definitions, in our case main and its dependencies, first we need to add the new definitions, then call compile:
I said earlier that there’ no build step… well, there isn’t!
compileis not going to type-check and test your code, because that’s already done once your code is in the database. Perhaps thecompilecommand should be calledexportto be more accurate: it just takes your already compiled code and stores the parts you need to run the entry function in a runnable file - which most people would probably think of as compiling… it’s a subtle difference, but an important one (and explains why runningcompilecompletes instantly!).
Now, we can run the program from any terminal:
▶ ucm run.compiled unison-cat.uc hi.txt
Hello Unison!
This is just a text file.
The generated .uc file has only 33069 bytes and seems to be a kind of multi-platform bytecode file, like a Java jar. It runs pretty fast as well, I can print a file of around 1MB in under 80ms, and a 25MB file piped to /dev/null in 0.4 seconds (considering the file is being fully loaded into memory and it’s just concatenating bytes from small 4KB chunks, that’s not too bad - it would be interesting to use a pre-allocated buffer instead, as Unison seems to have facilities for writing high performance code, but that will be left for a future post).
I believe Unison has plans to compile directly to native binaries as well, but when I attempted to run compile.native, it did not work. Something to wait for.
Updating code and reviewing changes
One of the main problems developers see with the Unison approach of letting go of our dear text source code files is that it makes it harder to review changes.
Well, but that’s not really true anymore: Unison provides decent tools to branch, change stuff, then generate the diffs before merging changes back to main, latest etc.
We can try it out by modifying the code in the previous sections to stop using Throw and using only Exception for error handling.
The first thing to do when modifying an existing code base is to fork it, so we can later get a diff easily, then cd into the new, forked namespace. The following shows how to do it from a fresh ucm session (including creating a main namespace to use as the development “branch”):
Notice that at the end, we are inside the namespace mylib.prs.improveErrorHandling, and that’s just a fork of mylib.main without any changes, so far.
Now, we want to edit the singleArgOrFail function to stop using Throw, so we type edit singleArgOrFail in ucm, which loads the current definition of that function into the scratch.u file:
singleArgOrFail : '{IO, Throw Text} Text
singleArgOrFail _ =
match catch getArgs with
Right (arg +: []) -> arg
Right _ -> throw "A single arg must be provided."
Left failure ->
use Text ++
throw <| "Unable to read arguments due to: " ++ message failure
By changing this function to use the Exception ability, we greatly simplify it as we don’t need to catch the Exception from getArgs anymore:
singleArgOrFail : '{IO, Exception} Text
singleArgOrFail _ =
match !getArgs with
arg +: [] -> arg
args -> Exception.raise <| failure "A single arg must be provided." args
Result:
I initially thought that Unison had failed to notice that main was using the previous definition, so it shouldn’t have allowed me to update this… but on further inspection, it turns out main still worked anyway because it already had the Exception ability… The code handling Throw became useless, but it still compiled fine!
Let’s revisit the current definition of main (type view main in ucm):
main : '{IO} ()
main _ =
errorHandler do
file = Throw.toException (e -> !(failure e)) singleArgOrFail
readUtf8 file |> printLine
This can now be simplified as well:
main : '{IO} ()
main _ =
errorHandler do
file = !singleArgOrFail
readUtf8 file |> printLine
Much nicer, and Unison allowed me to update it without issues.
But what if we made a breaking change? Like changing the return type of a function:
singleArgOrFail : '{IO, Exception} [Text]
singleArgOrFail = getArgs
On update:
Notice how Unison allows even this update, but it doesn’t actually change the dependent functions automatically… they keep referring to the old one, as you can see when I did view main above:
main : '{IO} ()
main _ =
errorHandler do
file = !#p8nm43hb6r
readUtf8 file |> printLine
Because the old definition now has no name, its actual hash is shown where it’s used. We need to use the todo command to see what else needs to change, then edit everything to hopefully use the new definition (or something else).
In this case, I just want to revert the latest change, so I undo it:
Notice how todo says everything is up-to-date now, and if you view main again, it will show the named function again!
You can read more details about how refactoring works in Unison at the How to update code section of the Documentation.
Code Review
This section of this blog post will probably be updated in the future as Unison is still defining how pull requests, patches and code review in general should work.
Check the Organizing your code base article for the current suggested way to manage this.
What follows is my personal suggestion on how you could do code review in your Unison code base.
Once we’re satisfied with our changes, we want to submit it for code review and hopefully merge the changes into main.
The Unison docs about Organizing your code base shows how to create a pull-request, push, pull and merge it using ucm.
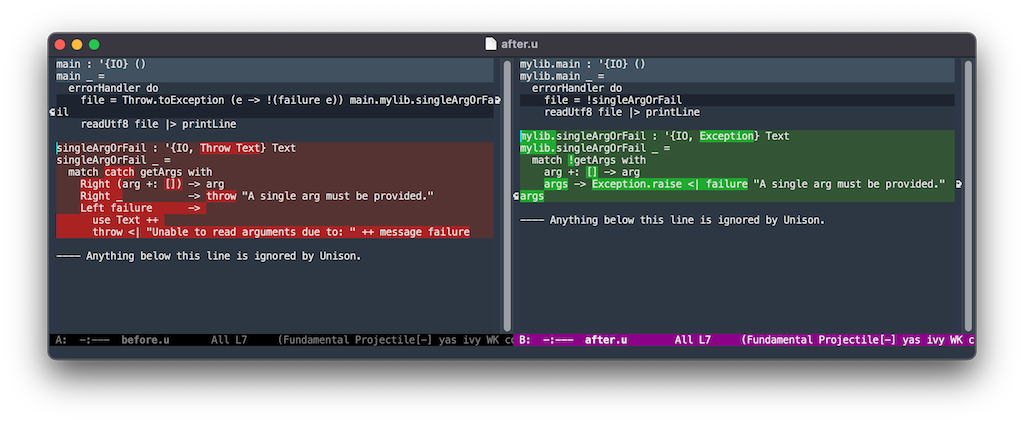
However, it doesn’t really explain how you can generate a proper diff to review the changes. I came up with the following procedure to get a single diff where I can see all the changes using whatever diff tool I like, for example emacs’ ediff. As long as you can see the diff between two files, this will work for you.
- create two empty
.ufiles:before.uandafter.u. - check what terms have been changed in the namespace with
diff.namespace. cdinto the base namespace.loadthebefore.ufile (as it’s empty, this just sets the current buffer forucm).editall the terms that have been modified.cdinto the new namespace.loadtheafter.ufile.editall the terms that have been modified.
This is what doing this looks like:
Now, the before.u and after.u files can be compared using your preferred diff tool.
For my current changes, it looks like this on emacs:
Hopefully, this procedure can be automated in the future, making this easier to do.
One last thing to do is merge the changes!
To do that, we use the merge command, obviously:
All changes are now merged into the .mylib.main namespace.
One problem I noticed is that, as you can see in the message from Unison above, a patch was created, which is normally used to update references to modified functions whose type were not changed by running patch patch. However, when I run that, I get a message This had no effect., so I think Unison just got confused somehow. You can get rid of the patch by running delete.patch patch.
And while you’re at it, if you don’t want the PR namespace to hang around, run also delete.namespace prs.improveErrorHandling.
Conclusion
Unison is an amazing new programming language that I am sure will not only start being used, very soon, in the niches that can mostly benefit from its purely functional nature and distributed computing friendliness, but it is also set to fundamentally influence what is expected of software development UX in the years to come.
It solves problems that most of us didn’t even know were problems that could be solved. And it’s just a very nice language all around. I found it quite a lot easier to grasp than Haskell, for example, while still feeling that it gives me more than enough power to write clean, reliable code without subjecting me to some hassle that most other languages would (long, complex builds, unreliable tests, dependency version conflicts…).
It’s not perfect, sure… working with namespaces and forks, pulls, merges is confusing with git, and perhaps even more when it’s such a fundamental part of using the language. The error messages, while normally top notch, can sometimes be quite unhelpful. But Unison has already come a long way from a couple of years ago, when I first tried it, and it’s rapidly improving recently.
There are many more interesting things that I didn’t find space to cover in this blog post, like code documentation, testing, using/publishing libraries (including some very nice libraries, like @runarorama/codec which makes it a breeze to work with binary encoding) and, specially, Unison support for distributed computing, which I think may not be ready for production usage just yet, and anyway I probably couldn’t do justice to the topic given my limited amount of time and knowledge in the area.
In any case, I hope more people will feel interested in Unison and help spread it, or at least its ideas, so that the language can develop to its full potential and maybe revolutionize the way software is made in the future.
✨ I posted all code from this blog post to my 🌎 Unison Share repository, where you can see what Unison live docs look like! ✨